AI Model Editing: आज के दौर में आर्टिफिशियल इंटेलिजेंस यानी AI Models और खासकर Large Language Models (LLMs) करोड़ों लोगों की रोज़मर्रा की जरूरत बन चुके हैं। जानकारी खोजने से लेकर कंटेंट लिखने और कोडिंग तक, ये मॉडल हर जगह इस्तेमाल हो रहे हैं। लेकिन हाल ही में सामने आई एक नई रिसर्च ने AI की सुरक्षा को लेकर गंभीर सवाल खड़े कर दिए हैं।
Model Edit करने से कैसे पैदा हो रहा है खतरा?
AI Model Editing मॉडल्स को जब किसी गलती को सुधारने या किसी संवेदनशील जानकारी को हटाने के लिए अपडेट किया जाता है, तो उसे Model Editing कहा जाता है। आमतौर पर इसमें “Locate-then-Edit” तकनीक का इस्तेमाल किया जाता है, जिसमें मॉडल के कुछ खास पैरामीटर्स बदले जाते हैं।
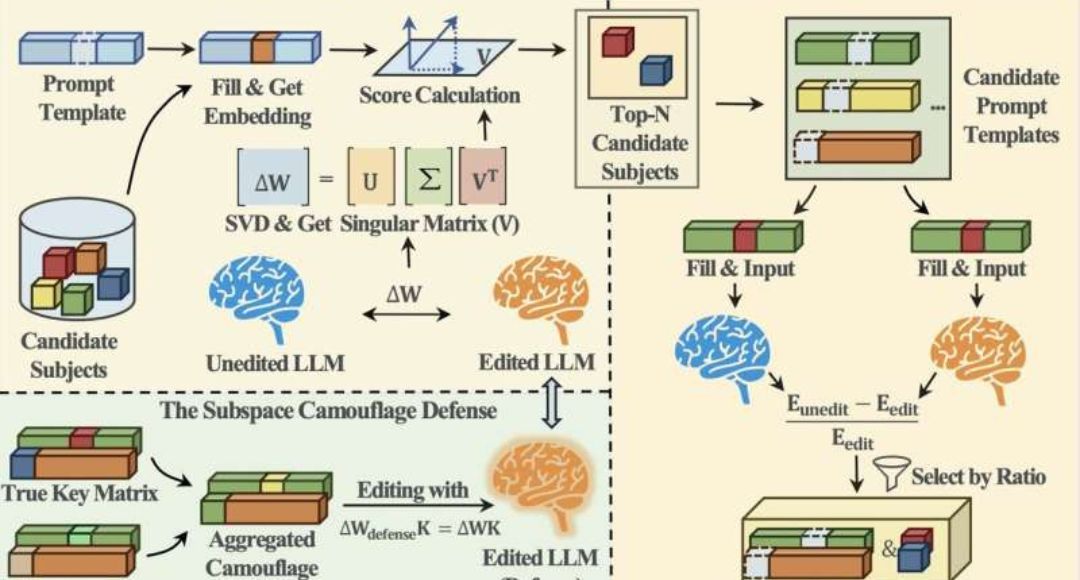
नई रिसर्च के मुताबिक, यही अपडेट्स एक तरह का डिजिटल फिंगरप्रिंट छोड़ देते हैं, जिससे साइबर अटैकर्स उस हटाई गई जानकारी को दोबारा रिकवर कर सकते हैं। यानी जिस डेटा को डिलीट समझा जाता है, वह पूरी तरह सुरक्षित नहीं रहता।
रिसर्च में क्या सामने आया?
AI Model Editing शंघाई Qi Zhi Institute, East China Normal University, Tsinghua University और Chinese Academy of Sciences के वैज्ञानिकों ने इस खतरे को विस्तार से समझाया है। रिसर्चर्स के अनुसार, LLMs को जब एडिट किया जाता है, तो उनके पैरामीटर अपडेट्स के जरिए संवेदनशील जानकारी का अंदाजा लगाया जा सकता है।
उन्होंने एक नया अटैक तरीका पेश किया है, जिसे KSTER Attack कहा गया है। यह दो स्टेज में काम करता है और मॉडल अपडेट्स की संरचना को पढ़कर डिलीट की गई जानकारी को फिर से निकाल सकता है।
किन AI Models पर हुआ सफल अटैक?
AI Model Editing रिसर्च के दौरान यह पाया गया कि यह सुरक्षा खामी कई पॉपुलर AI Models पर काम करती है, जिनमें शामिल हैं:
-
GPT-J
-
Llama-3
-
Qwen-2.5
AI Model Editing इन मॉडलों से एडिट की गई संवेदनशील जानकारी को काफी हद तक रिकवर किया जा सका, जो AI सिक्योरिटी के लिहाज से बेहद चिंताजनक है।
यूजर्स की प्राइवेसी पर क्यों है बड़ा खतरा?
AI Models को ट्रिलियन्स शब्दों के डेटा पर ट्रेन किया जाता है, जिसमें अनजाने में पर्सनल या संवेदनशील जानकारी भी स्टोर हो सकती है। अगर Model Editing के बाद भी डेटा को वापस निकाला जा सकता है, तो इसका सीधा असर यूजर्स की प्राइवेसी और डेटा सुरक्षा पर पड़ता है। यह खतरा खासतौर पर हेल्थ, फाइनेंस और पर्सनल कम्युनिकेशन जैसे संवेदनशील सेक्टर्स में AI के इस्तेमाल को लेकर चिंता बढ़ाता है।
क्या है इस खतरे से बचाव का तरीका?
AI Model Editing रिसर्चर्स ने इस समस्या से निपटने के लिए एक नई तकनीक सुझाई है, जिसे Subspace Camouflage कहा गया है। इसमें मॉडल अपडेट्स के अंदर जानबूझकर ऐसे डमी संकेत जोड़े जाते हैं, जिससे असली जानकारी को पहचानना मुश्किल हो जाए। इस तरीके से AI मॉडल की परफॉर्मेंस पर असर डाले बिना, डेटा लीक के खतरे को काफी हद तक कम किया जा सकता है।
आगे क्या बदलेगा AI सिक्योरिटी में?
इस रिसर्च ने AI इंडस्ट्री को एक साफ संदेश दिया है कि केवल मॉडल को एडिट करना ही पर्याप्त नहीं है। डेटा सुरक्षा और प्राइवेसी प्रोटेक्शन को AI डेवलपमेंट का अहम हिस्सा बनाना जरूरी है।

AI Model Editing आने वाले समय में AI कंपनियां और रिसर्च टीमें ज्यादा मजबूत सिक्योरिटी लेयर्स, बेहतर मॉडल एडिटिंग तकनीक और सुरक्षित अपडेट सिस्टम पर काम कर सकती हैं।
AI Models भले ही स्मार्ट होते जा रहे हों, लेकिन उनकी सुरक्षा अभी भी एक बड़ी चुनौती है। यह रिसर्च दिखाती है कि अगर सही सावधानी न बरती जाए, तो एडिट किया गया डेटा भी पूरी तरह सुरक्षित नहीं रहता। ऐसे में AI के सुरक्षित और जिम्मेदार इस्तेमाल के लिए नई तकनीकों और सख्त सिक्योरिटी उपायों की जरूरत पहले से कहीं ज्यादा बढ़ गई है।
Disclaimer: यह लेख विभिन्न रिसर्च रिपोर्ट्स और सार्वजनिक रूप से उपलब्ध तकनीकी जानकारी पर आधारित है। AI मॉडल्स और साइबर सिक्योरिटी से जुड़ी नीतियां समय-समय पर बदल सकती हैं। किसी भी तकनीकी निर्णय से पहले आधिकारिक स्रोतों की पुष्टि अवश्य करें।
Also Read
The Kerala Story 2 पर Anurag Kashyap का तीखा हमला, बोले यह फिल्म समाज को बांटने की कोशिश
भारत का अपना AI चैट ऐप ‘Indus’ लॉन्च, Sarvam ने OpenAI और Google को दी सीधी चुनौती
एक फोटो, हजारों लाइक्स 2026 के बेस्ट AI Image Editing & Sharing Tools